Lecture 15 - Artificial Neural Networks¶

![]()
15.1 Introduction to Artificial Neural Networks¶
Artificial Neural Networks (ANNs) are a class of machine learning algorithms that employ a network of connected computational units for information processing. ANNs are organized in layers, where each layer is made up of interconnected nodes (or computational units). The concept of ANNs is motivated by biological neural networks, and the development of ANNs is the result of an attempt to replicate the workings of the human brain. Hence, the nodes in ANNs are commonly referred to as neurons.
A simple ANN with one single layer is depicted in the following figure. The main layers in the ANN are:
Input layer, takes the input data in numerical format, where inputs to ANNs can be tabular data, images, texts, audio, etc.
Hidden layer, connects the input and the output layers. The neurons in the hidden layer process the input data and extract relevant patterns in the data.
Output layer, is the output of the network, which can be a continuous numeric value as in regression problems, or discrete class values as in classification problems.

Figure: One-layer ANN. Figure source: Wikipedia.
In general, ANNs can have multiple input layers, multiple hidden layers, and multiple output layers.
ANNs having more than one layer are commonly referred to as a Deep Neural Network (DNNs). Similarly, applying DNNs for solving a task is referred to as Deep Learning (DL).
Most current ANNs that are implemented for solving real-world tasks have multiple hidden layers. The number of hidden layers depends on the specific task, and typically ranges from 10 to 100. For solving complex tasks, ANNs with hundreds of hidden layers are used.
15.1.1 Elements of ANNs¶
The values of the connections between the neurons in ANNs are learned during a training phase. By using a training dataset, the values of the connections are updated with a goal of correctly predicting the outputs for given inputs.
The following figure depicts the operation of a single neuron in an ANN. The neuron is connected to other neurons in the previous layer via a set of inputs \(x_1, x_2, ..., x_m\) and weights \(w_1, w_2, ..., w_m\). Each neuron calculates the sum of products of the inputs and weights and a bias value, i.e., \(v = x_1 \cdot w_1 + x_2 \cdot w_2 + ... + x_m \cdot w_m + b\). The obtained value \(v\) is then passed through an activation function and the output \(y = \varphi(v)\) is transferred to the next layer in the network.
The weights and biases in an ANN are called network parameters. And very often the term weights is used to refer to both weights and biases as network parameters.
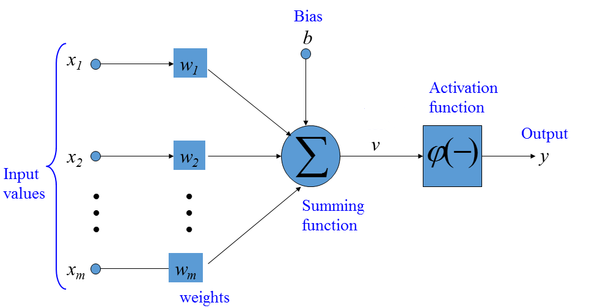
Figure: Artificial Neuron.
15.1.2 Common Activation Functions¶
Activation functions are applied to each neuron in ANNs to introduce non-linearities into the outputs of the neurons. Without non-linear activation functions, ANNs will simply learn linear mappings between the inputs and outputs. Calculating non-linear mappings between inputs and outputs gives ANNs the capabilities to learn complex tasks.
The most common activation functions in ANNs are:
Sigmoid activation function (logistic activation function): For a real-valued input, it outputs a value between 0 and 1. Sigmoid activation is used in the output layer for binary classification problems.
Tanh activation function (tangent hyperbolic activation function): It is similar to sigmoid activation function, but it outputs a value between -1 and 1. Tanh is rarely used in modern ANNs.
Softmax activation function: It is an extension of the sigmoid activation function for multiclass classification tasks, and it is used in the output layer for multiclass classification problems.
ReLU (Rectified Linear Unit) activation function: It outputs the input value if it is positive, and it outputs 0 if the input value is negative. In other words, this activation function just penalizes the negative inputs. ReLU is the most used activation function in the hidden layers of modern ANNs.
Leaky ReLU (Rectified Linear Unit) activation function: It is a modification of ReLU, where instead of outputting 0 for negative values, Leaky ReLU has a small negative slope. Some networks use Leaky ReLU instead of ReLU.
There are also several other modifications of ReLU activations such as GeLU (Gaussian error Linear Unit) and SeLU (Scaled exponential Linear Unit). Overall, ReLU is still the most common activation function.

Figure: Activation functions in ANNs. Figure source: link
15.1.3 Training ANNs¶
ANNs are trained by iteratively updating the network parameters (weights and biases) to minimize the difference between the network predictions and target labels.
Each iteration in the training phase includes the following 4 steps:
Forward pass (forward propagation)
Loss calculation
Error backpropagation (backward pass)
Model parameters update
Forward propagation is also known as forward pass, because the input data is passed through all hidden layers of the neural network toward the output layer to obtain the network predictions. For instance, if the input data is an image, the image is transformed through the layers of the network, and for classification problems, the output is a vector of predicted class probabilities.
Loss calculation is the second step, in which the loss of the network is calculated as a difference between the network output (predictions for each class) and the target ground-truth label for an image image. Common loss function for classification tasks is crossentropy loss, calculated as \(-\sum{y\cdot log(\hat{y})}\), where \(y\) is the ground-truth label and \(\hat{y}\) is the network prediction. For regression tasks commonly used loss functions include mean-squared error (calculated as \(\sum{(y- \hat{y})^2}\)) and mean-absolution error (calculated as \(\sum{|y- \hat{y}|}\)) between the network predictions and target ground-truth values.
Error backpropagation is also called backward pass or backward propagation (where the term backpropagation is short for backward propagation). In this step, the predicted outputs are traversed back through the network, from the last (output) layer backward toward the first (input) layer. During the backward step, the gradients of the loss with respect to the model parameters \(\nabla\mathcal{L}(𝜃)\) are calculated. If you recall from calculus, gradient is the vector of partial derivatives of a function, or for a loss function \(\mathcal{L}\) and network parameters \(𝜃\), the gradient is the vector \(\nabla\mathcal{L} = [\partial\mathcal{L}/\partial𝜃_i]\). The gradients quantify the impact of changing the parameters in the network to the predicted outputs. Automatic calculation of the gradients (automatic differentiation) is available in all current deep learning libraries, which significantly simplifies the implementation of deep learning algorithms.
Model parameters update is the last step in which new values for the model parameters are calculated and updated, typically using the Gradient Descent algorithm.

Figure: Steps in training ANNs.
A simple depiction of the Gradient Descent algorithm is shown in the next figure. The blue curve is a loss function \(\mathcal{L}\), and the gradient of the loss function \(\nabla\mathcal{L}\) gives the slope of the function. By updating the parameters in the opposite direction of the gradient of the loss \(\nabla\mathcal{L}\), the algorithm finds parameters \(𝜃\) for which the loss \(\mathcal{L}\) has a minimal value.

Figure: Steps in training ANNs.
Almost all modern neural networks are trained by applying a modified version of the Gradient Descent algorithm. Examples of such advanced Gradient Descent algorithms include Adam, SGD (Stochastic Gradient Descent), RMSprop, Adagrad, Nadam, and others. The deep learning libraries typically refer to the used algorithms for minimizing the loss of the model as optimizers.
Unlike the model training phase, predicting on test data (also known as inference) requires only a forward pass through the model, where for a given input instance the model outputs the prediction. For instance, in the above figure the output is a vector of class probabilities.
15.1.4 Types of ANN Architectures¶
The main types of ANN architectures are:
Fully-connected neural networks (FCNNs) (a.k.a. densely-connected neural networks, or multi-layer perceptrons)
Convolutional neural networks (CNNs)
Recurrent neural networks (RNNs)
Transformer neural networks (TNNs)
Graph neural networks (GNNs)
In this lecture, we will study Fully-connected NNs, and in the following lecture we will explore the other ANN architectures.
15.1.5 Fully-connected NNs¶
Fully-connected NNs are made of layers in which the neurons of any layer are connected to all other neurons of the preceding and succeeding layer. They are also called Densely-connected NNs, as well they are often referred to as Multi-Layer Perceptrons (MLPs).

Figure: Fully-connected NNs.
Fully-connected NNs are mostly used in simple tasks, such as for classification or regression tasks with tabular data. Their performance for tasks with images, text data, or other data formats is often inferior in comparison to CNNs, RNNs, TNNs, and GNNs.
15.2 Classification with ANNs¶
In calssification tasks, the goal is to predict the category, i.e., class label of the data samples.
Classification tasks can be divided into two main types:
Binary classification is classification with two classes. An example is to classify a tweet as positive or negative depending on its content. In the output layer, we need to use a single output neuron with a
sigmoidactivation function to output a value between 0 and 1. A threshold value (by default set to 0.5) can be used to differentiate between positive and negative classes. For example, if the value of the output neuron is 0.7, the tweet can be assigned as positive (since the value is greater than 0.5). The common loss function in binary classification isbinary crossentropy.Multiclass classification: is classification with three or more classes. An example is to classify a tweet into several classes, such as news, tech, sports, or weather. In the output layer, we need to use a number of output neurons equal to the number of classes, with a
softmaxactivation function. E.g., for the above tweet example, we will use 4 output neurons. Consequently, the output of the network will be a vector of class probabilities whose dimension is equivalent to the number of classes, such as [0.2 0.5 0.1 0.2] for the tweet example. The category with the maximum value is assigned as a class label to the tweet. In this case, if the four categories were news, tech, sports, or weather, the tweet will be assigned the class tech, since the network output of 0.5 for this class is the greatest. The commonly used loss functions in multiclass classification arecategorical crossentropy(when the target labels are in one-hot matrix encoding format) andsparse categorical crossentropy(when the target labels are in ordinal encoding format).
In both binary and multiclass classification problems, the hyperparameters of the ANN related to the number of input neurons, activation functions in the hidden layers, number of hidden layers, etc. depend on the specific problem we are solving.
Table: Typical values of hyperparameters in ANNs for classification
Hyperparameter |
Binary classifier |
Multiclass classifier |
|---|---|---|
Neurons in input layer |
Number of input features |
Number of input features |
Number of hidden layer(s) |
Depends on the problem, typically from 1-10 |
Depends on the problem, typically from 1-10 |
Neurons per hidden layer |
Depends on the problem, typically 10-100 |
Depends on the problem, typically 10-100 |
Neurons in output layer |
1 |
Neurons equivalent to number of classes |
Activation in hidden layers |
Mostly ReLU |
Mostly ReLU |
Activation in output layer |
sigmoid |
softmax |
Loss function |
binary cross entropy |
categorical crossentropy / sparse categorical crossentropy |
Optimizer |
Mostly Adam, SGD, RMSProp |
Mostly: Adam, SGD, RMSProp |
ANNs have many hyperparameters, and selecting the best values of the hyperparameters can be challenging. In the next lectures we will explore best practices for hyperparameter finetuning in ANNs.
15.2.1 Binary Classification¶
We will first implement an ANN for binary classification.
For this purpose, we will use again the Breast Cancer dataset which we also used in the previous lecture. Recall that the dataset has 569 samples, each having 30 features. The target labels are the benign or malignant class, hence it is a binary classification problem.
[1]:
# Import libraries
import numpy as np
import pandas as pd
import sklearn
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
import tensorflow as tf
from tensorflow import keras
# Print the version of tensorflow
print("TensorFlow version:{}".format(tf.__version__))
TensorFlow version:2.14.0
Loading the Dataset¶
The Breast Cancer dataset can be directly loaded from scikit-learn datasets. Let’s create a DataFrame df having the features and the target column as the last column to the right.
[2]:
# Load the dataset
from sklearn.datasets import load_breast_cancer
bc = load_breast_cancer()
df = pd.DataFrame(data=bc.data, columns=bc.feature_names)
df["target"] = bc.target
[3]:
# Check the shape of the dataset
df.shape
[3]:
(569, 31)
[4]:
# Show the first few rows
df.head()
[4]:
| mean radius | mean texture | mean perimeter | mean area | mean smoothness | mean compactness | mean concavity | mean concave points | mean symmetry | mean fractal dimension | ... | worst texture | worst perimeter | worst area | worst smoothness | worst compactness | worst concavity | worst concave points | worst symmetry | worst fractal dimension | target | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 17.99 | 10.38 | 122.80 | 1001.0 | 0.11840 | 0.27760 | 0.3001 | 0.14710 | 0.2419 | 0.07871 | ... | 17.33 | 184.60 | 2019.0 | 0.1622 | 0.6656 | 0.7119 | 0.2654 | 0.4601 | 0.11890 | 0 |
| 1 | 20.57 | 17.77 | 132.90 | 1326.0 | 0.08474 | 0.07864 | 0.0869 | 0.07017 | 0.1812 | 0.05667 | ... | 23.41 | 158.80 | 1956.0 | 0.1238 | 0.1866 | 0.2416 | 0.1860 | 0.2750 | 0.08902 | 0 |
| 2 | 19.69 | 21.25 | 130.00 | 1203.0 | 0.10960 | 0.15990 | 0.1974 | 0.12790 | 0.2069 | 0.05999 | ... | 25.53 | 152.50 | 1709.0 | 0.1444 | 0.4245 | 0.4504 | 0.2430 | 0.3613 | 0.08758 | 0 |
| 3 | 11.42 | 20.38 | 77.58 | 386.1 | 0.14250 | 0.28390 | 0.2414 | 0.10520 | 0.2597 | 0.09744 | ... | 26.50 | 98.87 | 567.7 | 0.2098 | 0.8663 | 0.6869 | 0.2575 | 0.6638 | 0.17300 | 0 |
| 4 | 20.29 | 14.34 | 135.10 | 1297.0 | 0.10030 | 0.13280 | 0.1980 | 0.10430 | 0.1809 | 0.05883 | ... | 16.67 | 152.20 | 1575.0 | 0.1374 | 0.2050 | 0.4000 | 0.1625 | 0.2364 | 0.07678 | 0 |
5 rows × 31 columns
Next, we will extract the features and the target labels, and we will split them into training and testing sets.
[5]:
# Extract the data and the labels
X = df.drop('target', axis=1)
y = df['target']
[6]:
from sklearn.model_selection import train_test_split
train_data, test_data, train_labels, test_labels = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)
[7]:
print('Training data inputs', train_data.shape)
print('Training labels', train_labels.shape)
print('Testing data inputs', test_data.shape)
print('Testing labels', test_labels.shape)
Training data inputs (455, 30)
Training labels (455,)
Testing data inputs (114, 30)
Testing labels (114,)
We will also scale the data with the MinMaxScaler. Recall again that we do not fit the scaler on the test dataset, but we only transform it.
[8]:
# Scaling the features to be between 0 and 1.
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
train_data = scaler.fit_transform(train_data)
test_data = scaler.transform(test_data)
Create the ANN¶
To create ANNs in this lectue we will use the Tensorflow-Keras library. Keras is part of TensorFlow, and if you notice in the above cell Keras is imported from TensorFlow.
To define the network architecture in Keras, we will use the data structures layers and models.
In the cell below we imported the needed layers and model classes and afterward we will create layers and model objects as instances of these classes.
For the ANN for this case we will use Input and Dense layers, as explained below. Model is a general class in Keras that is used to create new ANN models.
[9]:
# Import the layers and the model
from keras.layers import Input
from keras.layers import Dense
from keras.models import Model
TensorFlow-Keras requires the first layer in an ANN to be an Input layer, which will provide the shape of the input data in the form of a tuple. For the Breast Cancer dataset, there are 30 input features for training the model, and therefore, we will set the shape of the input data to (30,).
Note also that to create and train an ANN, we don’t need to provide information about the number of samples that are available for training or testing the model.
Let’s add two hidden layers. In Keras, Dense layers are fully-connected layers. Therefore, the layers dense1 and dense2 below are fully-connected layers, of which, the first layer has 30 units (or neurons), and the second layer has 15 neurons. The second argument in the Dense layers activation defines the activation function that is applied at each layer, and in this case we selected ReLU activations as the most common activation function. For each layer in Keras, we need to also
define the previous layer to which it connects. In this case, for dense1 the previous layer is the inputs layer, and dense2 follows the dense1 layer.
Finally, we added an output layer which is also a Dense layer. As we mentioned, for binary classification problems, the output layer has 1 neuron and it uses a sigmoid activation function. Preceding layer to the outputs layer is dense2 layer.
[10]:
# Define the layers in the network
inputs = Input(shape=(30,))
dense1 = Dense(units=30, activation='relu')(inputs)
dense2 = Dense(units=15, activation='relu')(dense1)
outputs = Dense(units=1, activation='sigmoid')(dense2)
After we define the layers, we will create a new model as an instance of the Model class. Let’s name the new instance model_1. The arguments in Model are the input and output layers, which we named in the above cell inputs and outputs.
[11]:
# Define the model by providing the inputs and outputs
model_1 = Model(inputs, outputs)
Now that we have created a model, we can inspect its architecture with the .summary() method. It provides a table with all layers in the network, the shape of the tensors that are output by each layer, and the number of parameters in each layer.
We can see that the first layer in the model expects the passed data to be of shape (None, 30). Here None is a placeholder, and specifies that the model can accept any number of samples that have 30 elements.
The output of the model is of shape (None, 1), meaning that it will output one single value for each data sample.
Also, we can see in the information under the table that this model has 1,411 trainable parameters, of which 930 are in the first hidden layer, 465 are in the second hidden layer, and 16 are in the output layer. During the model training, we will try to find optimal values of the network parameters that minimize the misclassification of the samples in the training dataset.
[12]:
# Model summary
model_1.summary()
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 30)] 0
dense (Dense) (None, 30) 930
dense_1 (Dense) (None, 15) 465
dense_2 (Dense) (None, 1) 16
=================================================================
Total params: 1411 (5.51 KB)
Trainable params: 1411 (5.51 KB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________
The graph of the network is also shown in the following figure. We can see the layers with all 1,411 connections in the network.

Figure: Graphical depiction of the network.
Compile the ANN¶
To be able to train the ANN model, first we need to compile it. During the compiling step, we will specify the loss function, optimizer, and metric.
The loss function (cost function) calculates the difference between the predicted class label by the model and the ground-truth target class label for each sample. If the difference is high, this means a higher loss.
In Keras and TensorFlow, there are three main crossentropy losses:
binary_crosssentropyused for binary classification with two classes.categorical_crossentropyused for multiclass classification with three and more classes, and the target labels are encoded in one-hot matrix format.sparse_categorical_crossentropyused for multiclass classification with three and more classes, and the target labels are encoded in ordinal format.
The optimizer is the optimization algorithm that is used to reduce the loss function. As we explained earlier, several different optimization algorithms are used with ANNs. In this case we will use Adam optimizer (which stands for Adaptive Moment Estimation). It is one of the fastest and most commonly used optimizers at present.
We will use accuracy as a metric, but we can also use AUC-ROC, or F1 score, or other metrics.
[13]:
model_1.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
Train the ANN¶
To train the model, Keras uses the fit method as in scikit-learn. Required arguments in fit include the training dataset and training labels, and additional arguments can include the number of epochs, batch size, verbose, and others.
The batch size below means that the fit method will repeatedly randomly select 64 samples from the training dataset, and use the batch of samples to train the model and update the model parameters. Therefore, for the training dataset of 455 samples, the updates will be repeated 455/64 = 7.1 times (i.e., the model will be updated 8 times to process the entire dataset). When all 455 samples in the training dataset are used, that is considered one epoch. In this case, the training will
continue for 100 epochs. Therefore, the parameters in the model will be updated 800 times in total (100 epoch x 8 steps per epoch = 800). Or, we can say that there are 800 training steps.
The verbose argument is set to 0, and the results from the training will not be displayed after the cell. Setting verbose to 1 will display a progress bar, and the default value of 2 will display the training loss and accuracy for each epoch.
Also, in the next cell we assign the output of the fit method to history, that is, we will save the training results in this variable, and later we will use it to plot the learning curves and analyze the model training.
[14]:
history = model_1.fit(train_data, train_labels, epochs=100, batch_size=64, verbose=0)
Evaluate the ANN on Test Data¶
Keras has a method evaluate that we can use for calculating the accuracy of the model. The arguments are test_data and test_labels. Note that evaluate() returns two values: the loss and accuracy of the model. Therefore, to print the accuracy we used the element with index 1 in evals_test.
[15]:
# Evaluate on test dataset
evals_test = model_1.evaluate(test_data, test_labels)
print("Classification Accuracy: ", evals_test[1])
4/4 [==============================] - 0s 3ms/step - loss: 0.0708 - accuracy: 0.9649
Classification Accuracy: 0.9649122953414917
[16]:
# evals_test contains the loss and accuracy of the model
evals_test
[16]:
[0.0707874745130539, 0.9649122953414917]
To obtain the predictions by the model on data samples, we will use the predict method in Keras, which works similarly to the predict method in scikit-learn.
[17]:
predictions = model_1.predict(test_data)
4/4 [==============================] - 0s 0s/step
Let’s check the shape of predictions to understand the output of the model, and compare it to the shape of test_data that we used in predict(). The test dataset has 114 samples, each with 30 features. Therefore, for each sample the model made a prediction and outputted one single value.
[18]:
predictions.shape
[18]:
(114, 1)
[19]:
# Compare to the shape of test_data
test_data.shape
[19]:
(114, 30)
Let’s inspect the output for the first 6 samples in test_data in the next cell. The shown values are difficult to interpret because they are displayed in scientific notation, therefore, in the following cell the values are shown rounded to 3 decimal places.
[20]:
predictions[:6]
[20]:
array([[1.8629966e-04],
[9.9987435e-01],
[7.2749399e-02],
[7.1462798e-01],
[1.4644288e-04],
[9.5147675e-01]], dtype=float32)
[21]:
np.around(predictions[:6], 3)
[21]:
array([[0. ],
[1. ],
[0.073],
[0.715],
[0. ],
[0.951]], dtype=float32)
Now we can notice that the predictions by the model have values between 0 and 1, and they can be considered as the probability of each sample to be either benign (0) or malignant (1).
This form of the outputs is expected, because we used a sigmoid activation function in the output layer, which restricts the outputs to be in the range between 0 and 1.
To assign the class label 0 or 1 to the predicted values, we can round the predictions with np.round() or tf.math.round() to return the closest integer. For example, for the prediction of 0.016, the class label is 0. For the prediction of 0.64, the class label is 1.
[22]:
# Class labels for the first predicted values
np.round(predictions[:6])
[22]:
array([[0.],
[1.],
[0.],
[1.],
[0.],
[1.]], dtype=float32)
We can also calculate the accuracy in the same way as did with scikit-learn models, by using the accuracy_score function. As expected, the calculated value for the accuracy is the same as the one calculated in the Keras evaluate method.
[23]:
from sklearn.metrics import accuracy_score
predictions = model_1.predict(test_data)
accuracy = accuracy_score(test_labels, np.round(predictions))
print('The test accuracy is {0:6.4f} %'.format(accuracy*100))
4/4 [==============================] - 0s 1ms/step
The test accuracy is 96.4912 %
To better understand the model performance, we can also display the confusion matrix.
[24]:
# Getting the confusion matrix
from sklearn.metrics import confusion_matrix
confmat = confusion_matrix(test_labels, np.round(predictions), labels=[1,0])
print(confmat)
[[70 2]
[ 2 40]]
As well as, we can use the function classification_report from scikit-learn, to display the precision, recall, F1-score, macro average accuracy, and weighted average accuracy per class.
[25]:
# Classification report: F1 score, Recall, Precision
from sklearn.metrics import classification_report
print(classification_report(test_labels, np.round(predictions)))
precision recall f1-score support
0 0.95 0.95 0.95 42
1 0.97 0.97 0.97 72
accuracy 0.96 114
macro avg 0.96 0.96 0.96 114
weighted avg 0.96 0.96 0.96 114
Visualize the Training Loss and Accuracy¶
The following figure visualizes the history of model training, and shows the training accuracy and loss of the model for each of the 100 training epochs. For this purpose, we used the history variable that we assigned to fit when training the model. It contains an attribute history.history which is a dictionary that stores the loss and accuracy of the model for each epoch.
These plots are called learning curves and are important for understanding the model performance. It is a good practice to always create a plot after training a model and analyze the learning curves.
For instance, we can notice that at the end of the 100th epoch, the training loss is still decreasing. Thus, we could have trained the model for longer than 100 epochs, and this could have resulted in higher accuracy. In the next lectures we will describe best practices for determining the number of epochs.
[26]:
# plot the accuracy and loss
train_loss = history.history['loss']
acc = history.history['accuracy']
epochsn = np.arange(1, len(train_loss)+1,1)
plt.figure(figsize=(12, 4))
plt.subplot(1,2,1)
plt.plot(epochsn, acc, 'b')
plt.grid(color='gray', linestyle='--')
plt.title('TRAINING ACCURACY')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.subplot(1,2,2)
plt.plot(epochsn,train_loss, 'b')
plt.grid(color='gray', linestyle='--')
plt.title('TRAINING LOSS')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.show()

15.2.2 Multiclass Classification¶
In this section, we will consider a multiclass classification problem. Our goal will be to train an ANN model for classifying the images in the Fashion MNIST dataset into 10 classes.
Loading the Dataset¶
Fashion MNIST dataset has 70,000 images, of which 60,000 are allocated for the training set and 10,000 for the test set. Examples of images in the dataset are shown in the next figure. Each is a grayscale images with 28 x 28 pixels.
![]()
The images are classified into the following 10 categories:
Label |
Description |
|---|---|
0 |
T-shirt/top |
1 |
Trouser |
2 |
Pullover |
3 |
Dress |
4 |
Coat |
5 |
Sandal |
6 |
Shirt |
7 |
Sneaker |
8 |
Bag |
9 |
Ankle boot |
The dataset can be imported directly from Keras datasets.
[27]:
# Load the Fashion MNIST dataset
fashion_mnist = tf.keras.datasets.fashion_mnist
(fashion_train, fashion_train_label), (fashion_test, fashion_test_label) = fashion_mnist.load_data()
[28]:
print('Training data inputs', fashion_train.shape)
print('Training labels', fashion_train_label.shape)
print('Testing data inputs', fashion_test.shape)
print('Testing labels', fashion_test_label.shape)
Training data inputs (60000, 28, 28)
Training labels (60000,)
Testing data inputs (10000, 28, 28)
Testing labels (10000,)
Let’s check the shape of the training data and the values in the first image.
[29]:
# Shape of each sample
fashion_train[0].shape
[29]:
(28, 28)
[30]:
# Pixels in the first train image
fashion_train[0]
[30]:
array([[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1,
0, 0, 13, 73, 0, 0, 1, 4, 0, 0, 0, 0, 1,
1, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 3,
0, 36, 136, 127, 62, 54, 0, 0, 0, 1, 3, 4, 0,
0, 3],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 6,
0, 102, 204, 176, 134, 144, 123, 23, 0, 0, 0, 0, 12,
10, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 155, 236, 207, 178, 107, 156, 161, 109, 64, 23, 77, 130,
72, 15],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0,
69, 207, 223, 218, 216, 216, 163, 127, 121, 122, 146, 141, 88,
172, 66],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 0,
200, 232, 232, 233, 229, 223, 223, 215, 213, 164, 127, 123, 196,
229, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
183, 225, 216, 223, 228, 235, 227, 224, 222, 224, 221, 223, 245,
173, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
193, 228, 218, 213, 198, 180, 212, 210, 211, 213, 223, 220, 243,
202, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 3, 0, 12,
219, 220, 212, 218, 192, 169, 227, 208, 218, 224, 212, 226, 197,
209, 52],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 6, 0, 99,
244, 222, 220, 218, 203, 198, 221, 215, 213, 222, 220, 245, 119,
167, 56],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 4, 0, 0, 55,
236, 228, 230, 228, 240, 232, 213, 218, 223, 234, 217, 217, 209,
92, 0],
[ 0, 0, 1, 4, 6, 7, 2, 0, 0, 0, 0, 0, 237,
226, 217, 223, 222, 219, 222, 221, 216, 223, 229, 215, 218, 255,
77, 0],
[ 0, 3, 0, 0, 0, 0, 0, 0, 0, 62, 145, 204, 228,
207, 213, 221, 218, 208, 211, 218, 224, 223, 219, 215, 224, 244,
159, 0],
[ 0, 0, 0, 0, 18, 44, 82, 107, 189, 228, 220, 222, 217,
226, 200, 205, 211, 230, 224, 234, 176, 188, 250, 248, 233, 238,
215, 0],
[ 0, 57, 187, 208, 224, 221, 224, 208, 204, 214, 208, 209, 200,
159, 245, 193, 206, 223, 255, 255, 221, 234, 221, 211, 220, 232,
246, 0],
[ 3, 202, 228, 224, 221, 211, 211, 214, 205, 205, 205, 220, 240,
80, 150, 255, 229, 221, 188, 154, 191, 210, 204, 209, 222, 228,
225, 0],
[ 98, 233, 198, 210, 222, 229, 229, 234, 249, 220, 194, 215, 217,
241, 65, 73, 106, 117, 168, 219, 221, 215, 217, 223, 223, 224,
229, 29],
[ 75, 204, 212, 204, 193, 205, 211, 225, 216, 185, 197, 206, 198,
213, 240, 195, 227, 245, 239, 223, 218, 212, 209, 222, 220, 221,
230, 67],
[ 48, 203, 183, 194, 213, 197, 185, 190, 194, 192, 202, 214, 219,
221, 220, 236, 225, 216, 199, 206, 186, 181, 177, 172, 181, 205,
206, 115],
[ 0, 122, 219, 193, 179, 171, 183, 196, 204, 210, 213, 207, 211,
210, 200, 196, 194, 191, 195, 191, 198, 192, 176, 156, 167, 177,
210, 92],
[ 0, 0, 74, 189, 212, 191, 175, 172, 175, 181, 185, 188, 189,
188, 193, 198, 204, 209, 210, 210, 211, 188, 188, 194, 192, 216,
170, 0],
[ 2, 0, 0, 0, 66, 200, 222, 237, 239, 242, 246, 243, 244,
221, 220, 193, 191, 179, 182, 182, 181, 176, 166, 168, 99, 58,
0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 40, 61, 44, 72, 41, 35,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0]], dtype=uint8)
[31]:
# A list of label names
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
[32]:
# Show the first image
index = 0
plt.figure(figsize=(4,4))
plt.imshow(fashion_train[index], cmap='gray')
# Display the label
image_label = fashion_train_label[index]
print('This type of image is: {}({})'.format(class_names[image_label], image_label))
This type of image is: Ankle boot(9)

We can also visualize several random images, to ensure that the labels match the images.
[33]:
import random
plt.figure(figsize=(6,6))
for index in range(6):
ax = plt.subplot(2, 3, index+1)
random_index = random.choice(range(len(fashion_train)))
plt.imshow(fashion_train[random_index], cmap='gray')
plt.title(class_names[fashion_train_label[random_index]])

Data Preprocessing¶
As expected, the pixel values in the images range from 0 to 255. To scale the values to the range from 0 to 1, we can just divide the training and test sets by 255.0.
[34]:
# Scaling the image pixels to be between 0 and 1
fashion_train = fashion_train/255.0
fashion_test = fashion_test/255.0
In addition, to create an ANN with fully-connected layers, we will need to reshape the images into one-dimensional arrays. Since each image has 28 x 28 = 784 pixels, let’s use reshape to flatten the images.
In the next lecture we will study Convolutional Neural Networks which are particularly suitable for processing image data, and they can work with 2-dimensional images without the need to flatten the arrays.
[35]:
fashion_train = fashion_train.reshape(-1, 784)
[36]:
fashion_test = fashion_test.reshape(-1, 784)
[37]:
# Check the shape
fashion_train.shape
[37]:
(60000, 784)
Create the ANN¶
In the next cell, we define the layers in the ANN. The architecture of the model is similar to the model we used in the previous example. Note that in the arguments for Dense layers we don’t need to specify the units keyword, as the first positional argument is the number of units (neurons).
Since this is a multiclass classification problem, notice that the number of neurons in output layer is 10, as it needs to match the number of class labels in the dataset. Also, we need to use softmax activation in the output layer.
[38]:
# Define the layers in the network
inputs = Input(shape=(784,))
dense1 = Dense(64, activation='relu')(inputs)
dense2 = Dense(32, activation='relu')(dense1)
outputs = Dense(10, activation='softmax')(dense2)
[39]:
fashion_classifier = Model(inputs, outputs)
Compile the ANN¶
To compile the model, we used the loss sparse_categorical_crossentropy because the labels are integers in ordinal encoding format. If the labels were in one-hot encoding format, we would have used categorical_crossentropy loss.
[40]:
# Compile the model
fashion_classifier.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
Train the ANN¶
To train the model, we pass the training data and labels. In this case, let’s train the model for 10 epochs, and use a batch_size of 32 images. Also, we used the default verbose, and the training results are displayed at the end of each epoch.
[41]:
history = fashion_classifier.fit(fashion_train, fashion_train_label, epochs=10, batch_size=32)
Epoch 1/10
1875/1875 [==============================] - 4s 2ms/step - loss: 0.5234 - accuracy: 0.8152
Epoch 2/10
1875/1875 [==============================] - 3s 2ms/step - loss: 0.3838 - accuracy: 0.8618
Epoch 3/10
1875/1875 [==============================] - 3s 2ms/step - loss: 0.3481 - accuracy: 0.8727
Epoch 4/10
1875/1875 [==============================] - 3s 2ms/step - loss: 0.3262 - accuracy: 0.8802
Epoch 5/10
1875/1875 [==============================] - 3s 2ms/step - loss: 0.3093 - accuracy: 0.8869
Epoch 6/10
1875/1875 [==============================] - 3s 2ms/step - loss: 0.2945 - accuracy: 0.8914
Epoch 7/10
1875/1875 [==============================] - 3s 2ms/step - loss: 0.2857 - accuracy: 0.8942
Epoch 8/10
1875/1875 [==============================] - 3s 2ms/step - loss: 0.2746 - accuracy: 0.8977
Epoch 9/10
1875/1875 [==============================] - 3s 2ms/step - loss: 0.2669 - accuracy: 0.9016
Epoch 10/10
1875/1875 [==============================] - 3s 2ms/step - loss: 0.2586 - accuracy: 0.9028
Evaluate the ANN on Test Dataset¶
By using the evaluate method in Keras, we can see that the classification accuracy on test data is 88.4%.
[42]:
# Evaluate on test dataset
evals_test = fashion_classifier.evaluate(fashion_test, fashion_test_label)
print("Classification Accuracy: ", evals_test[1])
313/313 [==============================] - 1s 2ms/step - loss: 0.3391 - accuracy: 0.8843
Classification Accuracy: 0.8842999935150146
We can also use predict() to obtain the model’s predictions.
[43]:
predictions = fashion_classifier.predict(fashion_test)
313/313 [==============================] - 0s 1ms/step
In the next call, we checked the shape of the predicted outputs, and since there are 10,000 test images and 10 classes, the output is (10000, 10).
[44]:
# check the shape of the predictions
predictions.shape
[44]:
(10000, 10)
Also, we displayed the predictions for the first 5 test images in the next cell. For each image, the model outputs probabilities for each of the 10 classes. The probabilities sum to 1. For instance, for the first test image, the model assigned the highest probability to the class with index 9.
[45]:
# Display the predictions for the first 5 test images
np.around(predictions[:5],3)
[45]:
array([[0. , 0. , 0. , 0. , 0. , 0.015, 0. , 0.031, 0. ,
0.954],
[0. , 0. , 0.996, 0. , 0.002, 0. , 0.002, 0. , 0. ,
0. ],
[0. , 1. , 0. , 0. , 0. , 0. , 0. , 0. , 0. ,
0. ],
[0. , 1. , 0. , 0. , 0. , 0. , 0. , 0. , 0. ,
0. ],
[0.087, 0. , 0.002, 0. , 0. , 0. , 0.91 , 0. , 0. ,
0. ]], dtype=float32)
To output the indices with the highest probability for each image we can use np.argmax.
[46]:
# Display the index with the highest probability for the first 5 test images
np.argmax(predictions[:5], axis=1)
[46]:
array([9, 2, 1, 1, 6], dtype=int64)
The ground-truth labels are also shown in the next cell, and they match correctly the predictions for the first 5 test images.
[47]:
# print the ground-truth label for the first 5 test images
fashion_test_label[:5]
[47]:
array([9, 2, 1, 1, 6], dtype=uint8)
Visualize the Training Loss and Accuracy¶
The learning curves are shown in the figure below. It becomes obvious that if we train the model for longer than 10 epochs, we can improve the classification performance.
[48]:
# plot the accuracy and loss
train_loss = history.history['loss']
acc = history.history['accuracy']
epochsn = np.arange(1, len(train_loss)+1,1)
plt.figure(figsize=(12, 4))
plt.subplot(1,2,1)
plt.plot(epochsn, acc, 'b')
plt.grid(color='gray', linestyle='--')
plt.title('TRAINING ACCURACY')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.subplot(1,2,2)
plt.plot(epochsn,train_loss, 'b')
plt.grid(color='gray', linestyle='--')
plt.title('TRAINING LOSS')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.show()

Re-train and Evaluate the ANN¶
Note that if we re-train the same model on the same training data and evaluate it on the same testing data, in most cases we will obtain similar, but different values for the accuracy!!!
The reason for this is because every time a model is trained, the values of the network parameters are randomly initialized to small values close to 0 (but not 0 though). Because of the random initialization, the model will converge to a different solution every time we train it.
Consequently, ANNs have a stochastic nature, meaning that every time we train a model we obtain a different output.
If the repeatability of the results is important, we can use a random seed to initialize the model parameters, and in that case, the accuracy will be the same if we re-train the model.
[49]:
fashion_classifier_2 = Model(inputs, outputs)
# Compile the model
fashion_classifier_2.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# Train the model
fashion_classifier_2.fit(fashion_train, fashion_train_label, epochs=10, batch_size=32, verbose=0)
# Evaluate on test dataset
evals_test = fashion_classifier_2.evaluate(fashion_test, fashion_test_label)
print("Classification Accuracy: ", evals_test[1])
313/313 [==============================] - 1s 2ms/step - loss: 0.3802 - accuracy: 0.8761
Classification Accuracy: 0.8761000037193298
15.3 Regression with ANNs¶
In regression tasks, we are interested in predicting single or multiple continuous values. The ANN architectures for regression tasks are similar to the architectures for classification tasks. The listed recommendations for the input and hidden layers are the same as for classification tasks. The number of neurons in the output layer depends on the problem. If we are predicting a single value it will be 1, and if we are predicting multiple values, the number of output neurons will be set to the number of predicted values.
The choice of activation functions depends on the problem, but in most cases, ReLU will work well in the hidden layers. Unlike ANNs for classification, ANNs for regression don’t need to have an activation function in the output layer, since the ANN outputs are continuous value(s).
We stated earlier that the loss function used in regression is usually Mean Squared Error(MSE), or if the dataset contains outliers, Mean Absolute Error (MAE) loss may be preferred.
A suitable choice for an optimizer is Adam. Other optimizers to try include SGD, RMSProp, Nadam, and others.
Table: Typical values of hyperparameters in ANNs for regression
Hyperparameter |
Typical value |
|---|---|
Neurons in input layer |
Same as the number of input features |
Number of hidden layer(s) |
Depends on the problem, typically from 1 to 10 |
Neurons per hidden layer |
Depends on the problem, typically from 10 to 100 |
Activation in hidden layers |
Mostly ReLU |
Activation in output layer |
None in most cases |
Loss function |
MSE or MAE |
Optimizer |
Mostly Adam, SGD, RMSProp |
Next, we will present an example of regression with ANNs, and for this purpose, we will use the California Housing Dataset that is available in scikit-learn.
We will load the California Housing Dataset from scikit-learn as a pandas DataFrame named housing. The objective of the regression task is to predict the median house value, shown in the column to the right.
[50]:
from sklearn.datasets import fetch_california_housing
housing = fetch_california_housing(as_frame=True).frame
housing.head()
[50]:
| MedInc | HouseAge | AveRooms | AveBedrms | Population | AveOccup | Latitude | Longitude | MedHouseVal | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 8.3252 | 41.0 | 6.984127 | 1.023810 | 322.0 | 2.555556 | 37.88 | -122.23 | 4.526 |
| 1 | 8.3014 | 21.0 | 6.238137 | 0.971880 | 2401.0 | 2.109842 | 37.86 | -122.22 | 3.585 |
| 2 | 7.2574 | 52.0 | 8.288136 | 1.073446 | 496.0 | 2.802260 | 37.85 | -122.24 | 3.521 |
| 3 | 5.6431 | 52.0 | 5.817352 | 1.073059 | 558.0 | 2.547945 | 37.85 | -122.25 | 3.413 |
| 4 | 3.8462 | 52.0 | 6.281853 | 1.081081 | 565.0 | 2.181467 | 37.85 | -122.25 | 3.422 |
[51]:
# Check the shape of the dataset
housing.shape
[51]:
(20640, 9)
We can check if there are missing values, and visualize the histograms of the features.
[52]:
housing.isnull().sum()
[52]:
MedInc 0
HouseAge 0
AveRooms 0
AveBedrms 0
Population 0
AveOccup 0
Latitude 0
Longitude 0
MedHouseVal 0
dtype: int64
[53]:
housing.hist(bins=20, figsize=(8,6))
plt.show()

In the next cell we will check if there are correlated features. We can notice high correlation between the house value and the number of bedrooms, which is expected. We can also notice high negative correlation between the price and longitude and latitude. In the following cell we plotted the house value versus longitude and latitude. The plot looks like the map of California, and we can see that houses that are closer to the coast are more expensive.
[54]:
correlation = housing.corr()
sns.heatmap(correlation, annot=True);
# plt.show()

[55]:
housing.plot(kind="scatter", x="Longitude", y="Latitude", c="MedHouseVal", cmap="jet", colorbar=True, legend=True, sharex=False, figsize=(6,6),)
plt.show()

And, if we check the median house value column, we can see that the values are in the range from 0 to 5.
[56]:
plt.plot(housing['MedHouseVal'], 'bo')
plt.show()

Let’s get the features and the target values, and create training and testing datasets.
[57]:
X = housing.drop('MedHouseVal', axis=1)
y = housing['MedHouseVal']
[58]:
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
[59]:
print('Training data inputs', X_train.shape)
print('Training labels', y_train.shape)
print('Testing data inputs', X_test.shape)
print('Testing labels', y_test.shape)
Training data inputs (16512, 8)
Training labels (16512,)
Testing data inputs (4128, 8)
Testing labels (4128,)
[60]:
# Scaling the features to be between 0 and 1
scaler = MinMaxScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
Let’s use a similar ANN architecture as in the classification tasks, with two Dense layers with ReLU activations, having 32 neurons each.
Since we would like to predict a single value, we will use 1 neuron in the output layer, without activation function.
[61]:
# Define the layers in the network
inputs = Input(shape=(8,))
dense1 = Dense(32, activation='relu')(inputs)
dense2 = Dense(32, activation='relu')(dense1)
outputs = Dense(1)(dense2)
[62]:
# Define the model by providing the inputs and outputs
model_2 = Model(inputs, outputs)
We can inspect the architecture of the ANN with the summary() method.
[63]:
model_2.summary()
Model: "model_3"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_3 (InputLayer) [(None, 8)] 0
dense_6 (Dense) (None, 32) 288
dense_7 (Dense) (None, 32) 1056
dense_8 (Dense) (None, 1) 33
=================================================================
Total params: 1377 (5.38 KB)
Trainable params: 1377 (5.38 KB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________
In this case, we will use mean_squared_error loss function. During training, the loss function will calculate the squared difference between the target value \(y\) and the predicted value \(\hat{y}\), calculated as \(\sum{(y - \hat{y})^2}\).
We can use the Adam optimizer for regression tasks as well. Note that we cannot measure accuracy as in classification tasks, therefore we don’t need to specify a performance metric. Alternatively, we can use mean-squared error, mean-absolute error, or R2 score as metrics.
[64]:
# Compile the model
model_2.compile(loss='mean_squared_error', optimizer='adam')
Similarly to classification tasks, to fit the model we will provide the training data and the target values. Let’s fit the model for 200 epochs.
[65]:
history = model_2.fit(X_train_scaled, y_train, epochs=200, verbose=0)
[66]:
# plot the loss
train_loss = history.history['loss']
epochsn = np.arange(1, len(train_loss)+1,1)
plt.figure(figsize=(4, 3))
plt.plot(epochsn,train_loss, 'b')
plt.grid(color='gray', linestyle='--')
plt.title('TRAINING LOSS')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.show()

We will again use predict to obtain the outputs of the model. Let’s check the predicted values for the first 10 test samples.
[67]:
predictions = model_2.predict(X_test_scaled[:10])
predictions
1/1 [==============================] - 0s 52ms/step
[67]:
array([[0.5398234],
[0.9367044],
[4.2926064],
[2.5250819],
[2.730356 ],
[1.5289242],
[2.1832035],
[1.4888892],
[2.338513 ],
[4.607725 ]], dtype=float32)
And we can compare the predicted values by the model to the target ground-truth values. It would be easier to create a plot of the predicted and target values, as in the following cell. We can see that for most values, the model predictions are close to the target values.
[68]:
# Ground-truth values
np.array(y_test[:10])
[68]:
array([0.477 , 0.458 , 5.00001, 2.186 , 2.78 , 1.587 , 1.982 ,
1.575 , 3.4 , 4.466 ])
[69]:
plt. figure(figsize=(8, 4))
plt.plot(predictions, 'rx', label='Predicted values')
plt.plot(np.array(y_test[:10]), 'go', label='Target values')
plt.legend()
plt.xlabel('Index')
plt.ylabel('Median House Value')
plt.show()

As we mentioned, metrics that we can use to evaluate the performance of regression models include mean-squared error (MSE), mean-absolute error (MAE), or R2 score. R2 score (or \(R^2\) pronounced ‘R squared’) is also called coefficient of determination, and evaluates the goodness of fit of regression models, by measuring the proportion of the variation in the target variable that is contained in the predicted variable.
In the next cell we imported these metrics from scikit-learn and calculated their values. Note that for MSE and MAE lower values indicate better performance, and for R2 score greater values indicate better performance.
[70]:
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
all_preds = model_2.predict(X_test_scaled)
print(f'MSE: {mean_squared_error(y_test, all_preds):7.4f}')
print(f'MAE: {mean_absolute_error(y_test, all_preds):7.4f}')
print(f'R2 score: {r2_score(y_test, all_preds):7.4f}')
129/129 [==============================] - 0s 1ms/step
MSE: 0.3119
MAE: 0.3678
R2 score: 0.7620
15.4 Saving and Loading Models in Keras¶
To save a model in Keras, we simply use the save() method, and provide the path to the directory.
The saved model contains the architecture with the layers, the weights for all layers in the model, and other information related to the used optimizer, loss, and metrics.
There are two possible formats to save the models into: HDF5 and Keras-TensorFlow SavedModel. If we provide the .h5 extension, then the saved model format is HDF5. If we provide the .keras extension, or if we don’t provide any extension, the model will be saved into Keras-TensorFlow SavedModel format.
Keras-TensorFlow SavedModel is the default, and it is recommended, since it is a newer format, and it saves additional information that is not included in the h5 file, such as losses and metrics (e.g., they can be useful if we wish to resume training).
Let’s use the Keras-TensorFlow SavedModel format to save the first classification model model_1 from Section 15.2.1 in the current working directory under the name classification_model.
[71]:
# Saving a model
model_1.save('classification_model.keras')
To load a saved model we will use the load_model method. It returns the architecture and weights of the saved model.
Let’s load the save model as model_3.
[72]:
# Loading a saved model
from keras.models import load_model
model_3 = load_model('classification_model.keras')
Afterward, we can use the loaded model as we would use any other model.
Let’s evaluate the model on the test dataset, just to check whether the returned value would be as expected.
[73]:
# Evaluate on test dataset
evals_test = model_3.evaluate(test_data, test_labels)
print("Classification Accuracy: ", evals_test[1])
4/4 [==============================] - 0s 0s/step - loss: 0.0708 - accuracy: 0.9649
Classification Accuracy: 0.9649122953414917
The summary of the model is displayed below.
[74]:
model_3.summary()
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 30)] 0
dense (Dense) (None, 30) 930
dense_1 (Dense) (None, 15) 465
dense_2 (Dense) (None, 1) 16
=================================================================
Total params: 1411 (5.51 KB)
Trainable params: 1411 (5.51 KB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________
Appendix¶
The material in the Appendix is not required for quizzes and assignments.
Keras-TensorFlow Model APIs¶
In Keras-TensorFlow, there are three ways to build ANNs:
Functional API
Sequential API
Subclassing API
Functional API in Keras¶
In the above examples, we used Functional API to build our models. Repeated again in the next cell is the first model example for classification which we used in Section 5.2.1.
[75]:
# Define the layers in the network
inputs = Input(shape=(30,))
dense1 = Dense(units=30, activation='relu')(inputs)
dense2 = Dense(units=15, activation='relu')(dense1)
outputs = Dense(units=1, activation='sigmoid')(dense2)
# Define the model by providing the inputs and outputs
model_1 = Model(inputs, outputs)
Functional API is the recommended API, because it is a more recent and advanced API in comparison to Sequential API, but it is simpler than the Subclassing API.
Functional API allows to build models with multiple inputs and outputs, or with custom connections between the hidden layers (examples are residual or skip connections, which we will study in the following lectures). Because of these characteristics, Functional API is well suited for creating networks for advanced tasks, such as object detection, segmentation, and others.
Sequential API in Keras¶
Sequential API is the initial option in Keras for model building, as well as it is the simplest.
The corresponding sequential model to the above model_1 is shown in the next cell. To create the model, we just add the layers in a sequence, one after another.
[76]:
from keras.models import Sequential
# Define the model and the layers in the network
model_1_seq = Sequential([
Dense(30, activation='relu'),
Dense(15, activation='relu'),
Dense(1, activation='sigmoid')])
After the model is created, the steps of compiling, training, and evaluation are the same, as shown in the next cell. As we explained above, the reason that the accuracy of model_1_seq is different than the accuracy of model_1 is not because of the API used, but because of the stochastic nature of ANNs.
[77]:
# Compile the model
model_1_seq.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
# Train the model
model_1_seq.fit(train_data, train_labels, epochs=100, batch_size=64, verbose=0)
# Evaluate on test dataset
evals_test_seq = model_1_seq.evaluate(test_data, test_labels)
print("Classification Accuracy: ", evals_test_seq[1])
4/4 [==============================] - 0s 0s/step - loss: 0.0672 - accuracy: 0.9825
Classification Accuracy: 0.9824561476707458
Sequential API is suitable for simple classification or regression tasks. However, this API is not suited for tasks with multiple inputs or outputs, or for networks with advanced architectures.
Subclassing API in Keras¶
Subclassing API is designed for building custom models and having full control of every step in the model building and training. It is the most suitable for building models with complex or custom architectures.
[78]:
# # Define the layers in the network
class Model1Subclass(Model):
def __init__(self, **kwargs):
super().__init__()
self.dense_1 = Dense(30, activation='relu')
self.dense_2 = Dense(15, activation='relu')
self.dense_3 = Dense(1, activation='sigmoid')
def call(self, inputs):
x = self.dense_1(inputs)
x = self.dense_2(x)
x = self.dense_3(x)
return x
# Instantiate the model
model_1_subclass = Model1Subclass()
[79]:
# Compile the model
model_1_subclass.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
# Train the model
model_1_subclass.fit(train_data, train_labels, epochs=100, batch_size=64, verbose=0)
# Evaluate on test dataset
evals_test_subclass = model_1_subclass.evaluate(test_data, test_labels)
print("Classification Accuracy: ", evals_test_subclass[1])
4/4 [==============================] - 0s 2ms/step - loss: 0.0725 - accuracy: 0.9825
Classification Accuracy: 0.9824561476707458
The Subclassing API in Keras is also similar to the model building in PyTorch. We will learn about PyTorch in an upcoming lecture.
References¶
Complete Machine Learning Package, Jean de Dieu Nyandwi, available at: https://github.com/Nyandwi/machine_learning_complete.
Implementing Linear Regression on California Housing Dataset, Debarshi Raj Basumatary, available at: https://medium.com/mlearning-ai/implementing-linear-regression-on-california-housing-dataset-378e14e421b7.
BACK TO TOP